Introduction¶
This tutorial will present and explain the code behind the paper titled Alignment of Historical Handwritten Manuscripts using Siamese Neural Network which was presented in ICDAR 2017. Feel free to download the paper from the link here. It is found under publications section.
Data Preparation: acquiring the data¶
We begin with data preparation, the input to the neural network. The data is annotated already and we will be using two manuscripts labeled 0206 and 0207, and the files can be downloaded from here.
The data format is simple. Each page is stored in an image file, and for each image file there is an XML file of the same name containing the annotations for this page.
Inside each folder there is a segments folder containing the result of parsing the annotation files and segmenting the relevant bounding boxes. Each bounding box for our annotation contains a subword from a page of the manuscript. We will be using these folders.
The first thing to do is to split the pages folders to two sets, one will be our training set, and the other one will be used for validation and testing sets. These two are split in half after the pairing process.
Folder 0206 consists of pages 004-1 to 015-2, totaling 24 pages. We will use pages 004-1 to 007-2 for testing and validation sets, leaving pages 008-1 to 015-2 for training.
Folder 0207 consists of pages 003-1 to 008-1, totaling 11 pages. Pages 003-1 to 004-2 for testing and validation sets, and pages 005-1 to 008-1 for training.
We will denote data_root as the path you wish to put the data at. Move the folders found under segments to the designated location as stated below.
Create a folder hierarchy for the data following this manner:
* data_root/train/0206 - manuscript 0206, folders 008-1 to 015-2
* data_root/train/0207 - manuscript 0207, folders 005-1 to 008-1
* data_root/train/pairs - will contain pairing files of the training pages
* data_root/test_valid/0206 - manuscript 0206, folders 004-1 to 007-2
* data_root/test_valid/0207 - manuscript 0207, folders 003-1 to 004-2
* data_root/test_valid/pairs - will contain pairing files of the test_valid pages
Resizing the data¶
The images are the original RGB images without any modifications, they were only segmented from the manuscript page following annotation information.
Before creating the pairs, the images need to be reshaped to dimensions of 83 by 69.
Data Preparation: generating pair information¶
We now create the pairs information. The annotated data we use is labeled with its textual value.
The deep Siamese network accepts a pair of images as input, and predicts whether the pair contains the same textual value or not, even if they do not really look the same in writing. If they contain the same textual value, they are called true pair, if they do not, then they are called false pair.
Some examples can be seen here:
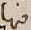
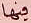


The first two images have the same textual label, even though they look differently, mainly due to writing the letter ـهـ differently. The same with the last two images. The writing style of the letter ـى is different, even though they are the same. Both of these cases are marked as true pair in the data. These cases are exactly where the neural network shines in contrary to older techniques.
Now we will proceed to create the pairs information for the deep neural network.
from os import listdir
from os import path
books = ['0207', '0206']
rootPath = '/majeek/data/train/'
# rootPath = '/majeek/data/test-valid/'
subWordMap = {}
subWordIndex = 0
for firstBook in books:
for secondBook in books:
if books.index(firstBook) >= books.index(secondBook):
continue
print('pairing ' + firstBook + ' with ' + secondBook + ' ...')
firstBookDirs = [d for d in listdir(rootPath + '/' + firstBook + '/')]
secondBookDirs = [d for d in listdir(rootPath + '/' + secondBook + '/')]
i = 0
for fbDir in firstBookDirs:
print(i, 'of', len(firstBookDirs))
with open(rootPath + firstBook + '/' + fbDir + '/' + fbDir + '.txt', 'r',
encoding='utf-8') as fbFile:
fImages = []
for line in fbFile.readlines():
imgName, label = line.split('\t')
fImages.append((imgName, label.strip()))
for sbDir in secondBookDirs:
pairs = []
labels = []
with open(rootPath + secondBook + '/' + sbDir + '/' + sbDir + '.txt', 'r',
encoding='utf-8') as sbFile:
sImages = []
for sLine in sbFile.readlines():
sImgName, sLabel = sLine.split('\t')
sImages.append((sImgName, sLabel.strip()))
for fImg in fImages:
for sImg in sImages:
if fImg[1] == sImg[1]:
if fImg[1] in subWordMap:
labels.append(subWordMap[fImg[1]])
else:
subWordMap[fImg[1]] = subWordIndex
labels.append(subWordIndex)
subWordIndex += 1
pairs.append((firstBook + '-' + fbDir + '-' +
fImg[0] + '.png',
secondBook + '-' + sbDir + '-' +
sImg[0] + '.png', subWordMap[fImg[1]]
))
with open(path.join(rootPath + 'pairs/',
firstBook + '-' + fbDir + '^' + secondBook +
'-' + sbDir + '.txt'),
'w', encoding='utf-8') as fp:
fp.write('\n'.join('%s\t%s\t%s' % x for x in pairs))
fp.write('\n')
i += 1
The code above will be executed twice, once for the training data, and another for the test_valid data, and can be done by changing the value of rootPath value.
The purpose of the code above is to generate a pairing as follows:
- For each image i in page j from manuscript 0206 we pair it with every image k in page l from manuscript 0207.
- For each two pages i, l we create a file containing all their pairs.
- Each line in the file contains the image i, image k, and a numeric value acting as a label for each subword form.
Creating the pickles: training, validation, and testing sets¶
This part handles the creation of the three subsets needed for training the model, validating, and testing it.
The pairing data created in the previous section was not used (but would've been) in the following code below, but instead the new labeling is used to create both true pair and false pair data. The new labeling is numeric, while the older labeling was using utf-8 encoding.
Auxiliary Function¶
We begin with a helper function. The helper function receives a list of pairs, shuffles it, and returns the first limit pairs.
import numpy as np
def shuffle_and_limit(pairs, limit):
filter_dec = {}
for word_part in pairs.keys():
good_pairs = pairs[word_part]
np.random.shuffle(good_pairs)
filter_dec[word_part] = good_pairs[:limit]
return filter_dec
Creating True Pairs¶
The next function receives two dictionaries, and generates a list of all possible true pairs for all subword forms.
- word_part_imgs_bX - a dictionary made for all page of manuscript.
- key is subword form, denoted by a numeric value.
- value is set of names of images for this key.
- b1 is first manuscript data, b2 is second manuscript data.
- min_instances - a threshold used for minimum numbers of true pairs possible per subword form.
def create_true_pairs(word_part_imgs_b1, word_part_imgs_b2, min_instances):
true_pairs = {}
for word_part in word_part_imgs_b1.keys():
b1_instances = list(word_part_imgs_b1[word_part])
b2_instances = list(word_part_imgs_b2[word_part])
if len(b1_instances) * len(b2_instances) >= min_instances:
for b1_instance in b1_instances:
for b2_instance in b2_instances:
if word_part in true_pairs.keys():
true_pairs[word_part].append([b1_instance, b2_instance])
else:
true_pairs[word_part] = [[b1_instance, b2_instance]]
return true_pairs
Creating False Pairs¶
In the same manner of creating true pairs, now we wish to create the same amount of false pairs following the size of true pairs for each subword form.
import numpy as np
def create_false_pairs(word_part_imgs_b1, word_part_imgs_b2, true_pairs):
false_pairs = {}
for word_part in true_pairs.keys():
positive_instances = len(true_pairs[word_part])
b1_instances = list(word_part_imgs_b1[word_part])
b2_instances = []
for b2_word_part in word_part_imgs_b2:
if b2_word_part != word_part:
b2_instances.extend(word_part_imgs_b2[b2_word_part])
b2_instances = list(set(b2_instances))
false_pairs[word_part] = []
while positive_instances > 0:
b1_instance = b1_instances[random.randint(0, len(b1_instances) - 1)]
b2_instance = b2_instances[random.randint(0, len(b2_instances) - 1)]
try:
first_img = os.path.getsize(b1_instance)
second_img = os.path.getsize(b2_instance)
if first_img != 0 and second_img != 0:
if not ([b1_instance, b2_instance] in false_pairs[word_part]):
false_pairs[word_part].append([b1_instance, b2_instance])
positive_instances -= 1
except OSError as e:
print(e)
return false_pairs
Creating a Dataset¶
Now using the two functions above, we can create both parts of a dataset, true pairs, and false pairs. We ensure both the uniform distribution of data over its classes as well as the randomness of data. The uniformity is saved over two aspects: uniform distribution for each subword form, as well as uniform distribution for each type of the two types of pairs. This function will be used to create the three subsets we need.
import codecs
def create_pairs(root_path, limit, min_instances):
path = root_path + 'pairs/'
all_files = [f for f in listdir(path) if isfile(join(path, f))]
word_part_imgs_b1 = {}
word_part_imgs_b2 = {}
for one_file in all_files:
parts = one_file.split('+')
first_book = root_path + parts[0].split('-')[0] + '/'
second_book = root_path + parts[1].split('-')[0] + '/'
first_dir = parts[0].split(parts[0].split('-')[0] + '-')[1]
second_dir = parts[1].split(parts[1].split('-')[0] + '-')[1]
first_dir = first_book + first_dir + '/CCs/'
second_dir = second_book + second_dir[:-4] + '/CCs/'
with codecs.open(path + one_file, 'r', "utf-8") as in_fd:
for line in in_fd:
line = line.strip().split()
first_file = first_dir + line[0]
second_file = second_dir + line[1]
try:
if line[2] in word_part_imgs_b1.keys():
word_part_imgs_b1[line[2]].add(first_file)
else:
word_part_imgs_b1[line[2]] = set()
word_part_imgs_b1[line[2]] .add(first_file)
if line[2] in word_part_imgs_b2.keys():
word_part_imgs_b2[line[2]].add(second_file)
else:
word_part_imgs_b2[line[2]] = set()
word_part_imgs_b2[line[2]].add(second_file)
except OSError as e:
print(e)
print('creating true pairs..')
true_pairs = create_true_pairs(word_part_imgs_b1, word_part_imgs_b2, limit, min_instances)
true_pairs = shuffle_and_limit(true_pairs, limit)
print('creating false pairs..')
false_pairs = create_false_pairs(word_part_imgs_b1, word_part_imgs_b2, true_pairs)
false_pairs = shuffle_and_limit(false_pairs, limit)
print('forms count =', len(true_pairs))
print('wordparts =', true_pairs.keys())
return true_pairs, false_pairs
Training Set¶
Using the functions above we are now able to create the training set. This function accepts two lists, one containing the true pairs, and another containing false pairs, then we combine them together into one dataset. We provide a label of 1 for true pairs, and a label of 0 for false pairs in the dataset.
import numpy as np
def prepare_trainset(true_pairs, false_pairs):
train_pairs = []
train_y = []
for key in true_pairs.keys():
key_true_pairs = true_pairs[key]
ktp_len = len(key_true_pairs)
key_false_pairs = false_pairs[key]
kfp_len = len(key_false_pairs)
train_pairs.extend(key_true_pairs)
train_y.extend(itertools.repeat(1, ktp_len))
train_pairs.extend(key_false_pairs)
train_y.extend(itertools.repeat(0, kfp_len))
train = list(zip(train_pairs, train_y))
np.random.shuffle(train)
train = np.array(train)
return train[:, 0], train[:, 1]
Validation and Testing Sets¶
We do the same for both validation and testing sets. In this function we generate one dataset segmented in half. The first half is designated validation set, and the second half for testing set.
import numpy as np
def prepare_valid_test(true_pairs, false_pairs):
test_pairs = []
test_y = []
valid_pairs = []
valid_y = []
for key in true_pairs.keys():
key_true_pairs = true_pairs[key]
ktp_len = len(key_true_pairs)
key_false_pairs = false_pairs[key]
kfp_len = len(key_false_pairs)
test_pairs.extend(key_true_pairs[:int(ktp_len * .5)])
test_y.extend(itertools.repeat(1, int(ktp_len * .5)))
test_pairs.extend(key_false_pairs[:int(kfp_len * .5)])
test_y.extend(itertools.repeat(0, int(kfp_len * .5)))
valid_pairs.extend(key_true_pairs[int(ktp_len * .5):])
valid_y.extend(itertools.repeat(1, ktp_len - int(ktp_len * .5)))
valid_pairs.extend(key_false_pairs[int(kfp_len * .5):])
valid_y.extend(itertools.repeat(0, kfp_len - int(kfp_len * .5)))
test = list(zip(test_pairs, test_y))
np.random.shuffle(test)
valid = list(zip(valid_pairs, valid_y))
np.random.shuffle(valid)
test = np.array(test)
valid = np.array(valid)
return test[:, 0], test[:, 1], valid[:, 0], valid[:, 1]
Creating, Saving and Loading the Datasets¶
We store the three subsets as pickle files for future use. We only create the three datasets once, store them into pickle files in the first time. Then, we load the pickle files for training or testing without the need to recreate them. The files are stored under root_path.
For this matter we use two flag, if set true, the requested subset is created, otherwise it is loaded:
- create_train - if set to true then the training set is created, otherwise loaded.
- create_test_valid - if set to true then both testing and validation sets are created, otherwise loaded.
Finally, the data is rounded to nearest batch_size.
import pickle
import numpy as np
np.random.seed(1337)
root_path = '/majeek/data/'
create_train = True
create_test_valid = True
batch_size = 100
if create_train:
true_pairs, false_pairs = create_pairs(root_path + 'train/', limit, min_instances)
tr_pairs, tr_y = prepare_trainset(true_pairs, false_pairs)
with open(root_path + 'trainset.pkl', 'wb') as out_fd:
pickle.dump([tr_pairs, tr_y], out_fd)
print('done preparing training set.')
if create_test_valid:
true_pairs, false_pairs = create_pairs(root_path + 'test-valid/', limit, min_instances)
te_pairs, te_y, va_pairs, va_y = prepare_valid_test(true_pairs, false_pairs)
with open(root_path + 'testset.pkl', 'wb') as out_fd:
pickle.dump([te_pairs, te_y], out_fd)
with open(root_path + 'validset.pkl', 'wb') as out_fd:
pickle.dump([va_pairs, va_y], out_fd)
print('done preparing test/validation sets.')
if not create_train:
with open(root_path + 'trainset.pkl', 'rb') as in_fd:
pkl = pickle.load(in_fd)
tr_pairs = pkl[0]
tr_y = pkl[1]
if not create_test_valid:
with open(root_path + 'testset.pkl', 'rb') as in_fd:
pkl = pickle.load(in_fd)
te_pairs = pkl[0]
te_y = pkl[1]
with open(root_path + 'validset.pkl', 'rb') as in_fd:
pkl = pickle.load(in_fd)
va_pairs = pkl[0]
va_y = pkl[1]
x = len(tr_pairs) % batch_size
tr_pairs = tr_pairs[:len(tr_pairs) - x]
tr_y = tr_y[:len(tr_y) - x]
x = len(te_pairs) % batch_size
te_pairs = te_pairs[:len(te_pairs) - x]
te_y = te_y[:len(te_y) - x]
x = len(va_pairs) % batch_size
va_pairs = va_pairs[:len(va_pairs) - x]
va_y = va_y[:len(va_y) - x]
print('training size:', len(tr_pairs))
print('testing size:', len(te_pairs))
print('validation size:', len(va_pairs))
The Siamese Neural Network: Architecture Code¶
This network consists of several parts:
* Network twin: Convolutional neural network
* Loss function: binary cross-entropy
* Final activation function: sigmoid applied on the absolute linear distance between the Siamese twins.
* Optimizer: RMSprop
* Metric: accuracyfrom keras.models import Sequential, Model, load_model
from keras.layers import Dense, Dropout, Lambda, Flatten, Input, MaxPooling2D, Convolution2D
from keras import backend as K
from keras.callbacks import ModelCheckpoint
def create_base_network(input_dim):
seq = Sequential()
seq.add(Convolution2D(64, (5, 5), padding='same', activation='relu', input_shape=input_dim))
seq.add(MaxPooling2D(padding='same', pool_size=(2, 2)))
seq.add(Convolution2D(128, (4, 4), padding='same', activation='relu'))
seq.add(MaxPooling2D(padding='same', pool_size=(2, 2)))
seq.add(Convolution2D(256, (3, 3), padding='same', activation='relu'))
seq.add(MaxPooling2D(padding='same', pool_size=(2, 2)))
seq.add(Convolution2D(512, (2, 2), padding='same', activation='relu'))
seq.add(Flatten())
seq.add(Dense(4096, activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(4096, activation='relu'))
return seq
This is the network twin used in the Siamese neural network. Four convolution layers separated by a max pooling layer. Then two dense layers separated by a DropOut layer.
import pickle
import numpy as np
from keras.optimizers import RMSprop
input_dim = (83, 69, 1)
train = True
batch_size = 100
def abs_diff_output_shape(shapes):
shape1, shape2 = shapes
return shape1
def get_abs_diff(vects):
x, y = vects
return K.abs(x - y)
base_network = create_base_network(input_dim)
input_a = Input(shape=input_dim)
input_b = Input(shape=input_dim)
processed_a = base_network(input_a)
processed_b = base_network(input_b)
abs_diff = Lambda(get_abs_diff, output_shape=abs_diff_output_shape)([processed_a, processed_b])
flattened_weighted_distance = Dense(1, activation='sigmoid')(abs_diff)
checkpoint = ModelCheckpoint(root_path + 'best_model', monitor='val_acc',
save_best_only=True, mode='max')
if train:
model = Model(inputs=[input_a, input_b], outputs=flattened_weighted_distance)
opt = RMSprop()
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy'])
print(model.summary())
print('training steps=', len(tr_pairs) / batch_size)
print('validation steps=', len(va_pairs) / batch_size)
model.fit_generator(generate_arrays_from_file(tr_pairs, tr_y),
len(tr_pairs) / batch_size,
epochs=nb_epoch,
callbacks=[checkpoint],
validation_data=generate_arrays_from_file(va_pairs, va_y),
validation_steps=len(va_pairs) / batch_size)
else:
model = load_model(root_path + 'best_model')
model = load_model(root_path + 'best_model')
# compute final accuracy on training and test sets
tr_score, tr_acc = model.evaluate_generator(generate_arrays_from_file(tr_pairs, tr_y),
len(tr_pairs) / batch_size)
print('* Accuracy on the training set: {:.2%}'.format(tr_acc))
te_score, te_acc = model.evaluate_generator(generate_arrays_from_file(te_pairs, te_y),
len(te_pairs) / batch_size)
print('* Accuracy on the test set: {:.2%}'.format(te_acc))
va_score, va_acc = model.evaluate_generator(generate_arrays_from_file(va_pairs, va_y),
len(va_pairs) / batch_size)
print('* Accuracy on the validation set: {:.2%}'.format(va_acc))
Finally, the batch loading assistant function used in fit_generator. The function loads the images and feeds them to the network each batch.
from scipy import misc
def generate_arrays_from_file(pairs, ys, batch_size=100):
i = 0
while True:
first = []
second = []
batch_ys = []
success = 0
for pair in pairs[i:]:
try:
first_file = misc.imread(pair[0], flatten=True) / 255.
second_file = misc.imread(pair[1], flatten=True) / 255.
first.append(np.array(first_file))
second.append(np.array(second_file))
batch_ys.append(ys[i])
success += 1
except (IOError, OSError, AttributeError) as e:
print(e)
finally:
i += 1
if success == batch_size:
break
f = np.asarray(first)
f = f.reshape(f.shape + (1,))
s = np.asarray(second)
s = s.reshape(s.shape + (1,))
if i == (len(pairs)/batch_size)*batch_size:
i = 0
yield ([f, s], batch_ys)
Alignment Algorithm¶
The alignment algorithm uses the trained model to predict whether each pair consists of the same text or not. As a result of prediction we receive a value in range of [0,1]. For the alignment process we do not round these results, since they provide similarity rating. The algorithm also uses the Munkres implementation of the Hungarian Method (Kuhn-Munkres algorithm) to find the best fit possible for each window.
Data for Alignment¶
There are two sets of manuscripts suitable for alignment. Their text is almost identical with minor alterations such as, words swapped, omitted, or inserted.
There are two sets of manuscripts that contain similar text:
- 0206, and 0207, pages 004-1(image 0) to 015-2 and 003-1(image 143) to 008-1, respectively.
- 3158466 and 3249138, pages 006-1(image 45) to 018-1 and 007-1(image 0) to 018-1, respectively.
Auxiliary Function¶
This helper function retrieves annotation value, in utf-8, for a given image of a manuscript.
def get_annotation(img_idx, manuscript_path):
with open(manuscript_path, 'r') as in_f:
for i in range(0, img_idx):
val = in_f.readline().decode('utf-8')
k, v = val.split('\t')
return v.rstrip()
Alignment Iteration¶
The code below applies one iteration of the alignment algorithm. The algorithm receives the starting index of both manuscripts, then generates the prediction matrix for all pairs of images in range of starting image index and window size.
For image
def alignment_iteration(img_idx_manuscript1, img_idx_manuscript2, window_size, model, path1, path2):
all_paths = []
for idx1 in range(img_idx_manuscript1, img_idx_manuscript1 + window_size):
for idx2 in range(img_idx_manuscript2, img_idx_manuscript2 + window_size):
all_paths.append([path1 + str(idx1) + '.png', path2 + str(idx2) + '.png'])
print('loading image pairs... for indexes %d, %d' % (img_idx_manuscript1, img_idx_manuscript2))
first = []
second = []
for pair in all_paths:
first_file = misc.imread(pair[0], flatten=True) / 255.
second_file = misc.imread(pair[1], flatten=True) / 255.
first.append(np.array(first_file))
second.append(np.array(second_file))
f = np.asarray(first)
f = f.reshape(f.shape + (1,))
s = np.asarray(second)
s = s.reshape(s.shape + (1,))
sys.stdout.write('predicting... ')
predicts = model.predict([f, s])
predicts = np.array(predicts)
print('done')
for a, pred in zip(all_paths, predicts):
a1 = a[0].split('/').pop()
a2 = a[1].split('/').pop()
print(a1, a2, pred[0])
predicts = np.reshape(predicts, (window_size, window_size))
return predicts
Choosing best fit for the current window¶
After receiving a prediction matrix. We now apply the Hungarian method to find the best-fit, highest cost, pairing result out of all possibilities. Munkres implementation has a complexity of O(n^3). It can be found under Munkres python library.
def find_best_fit(predictions, b1, root1, page1, b2, root2, page2):
m = Munkres()
idx = m.compute(1 - predictions)
total = 0
for r, c in idx:
v = predictions[r][c]
total += v
annotation1 = get_annotation(b1 + r, root1 + page1 + page1 + '.txt')
annotation2 = get_annotation(b2 + c, root2 + page2 + page2 + '.txt')
print('(R %s [%d], %s [%d]) -> %f' % (annotation1, b1 + r - 1, annotation2, b2 + c - 1, v))
print('total cost: %f' % total)
return idx
Aligning a Page of Two Manuscripts¶
The next function is the main function. It aligns two pages, first taken from one manuscript, and another taken from another manuscript. It receives all needed parameters of two manuscripts pages(detailed at next section), and applies a sliding window on both manuscripts, each time using the model to predict similarity between every two pair found in the sliding window, then applies the Hungarian method to find the optimal fit.
It then moves ahead one subword at a time, applying the same iterative process once more, increasing or decreasing the confidence of the predictions.
Finally, it calculates the accuracy rating of the process.
def align_manuscripts_page(root1, path1, page1, begin1, root2, path2, page2, begin2, last_index, window_size, model_path):
print('loading model...')
model = load_model(model_path)
results = {}
curr1 = begin1
curr2 = begin2
while curr1 < last_index:
p = alignment_iteration(curr1, curr2, window_size, model, path1, path2)
curr1 += 1
curr2 += 1
indexes = find_best_fit(p, curr1, root1, page1, curr2, root2, page2)
for row, column in indexes:
value = p[row][column]
key1 = curr1 + row
key2 = curr2 + column
if (key1, key2) in results:
results[(key1, key2)] += value
else:
results[(key1, key2)] = value
final_results = []
picks = []
print('total picks =', len(picks))
for i in range(begin1 + 1, begin1 + window_size + last_index - 1):
picks.append([(key, results[key]) for key in results if key[0] == i])
print(picks)
for pick in picks:
print(pick)
rez = max(pick, key=lambda x: x[1])
final_results.append(rez)
success = 0.
total = 0
for r in final_results:
val1 = get_annotation(r[0][0], root1 + page1 + page1 + '.txt')
val2 = get_annotation(r[0][1], root2 + page2 + page2 + '.txt')
confidence = r[1]
if confidence < 1.0:
print('LOW CONFIDENCE, %d, %d, %s, %s, %s' % (r[0][0], r[0][1], r[1], val1, val2))
continue
elif val1 == val2:
print('success, %d, %d, %s, %s, %s' % (r[0][0], r[0][1], r[1], val1, val2))
success += 1
total += 1
else:
print('ERROR, %d, %d, %s, %s, %s' % (r[0][0], r[0][1], r[1], val1, val2))
total += 1
accuracy = success/total*100
return accuracy
To Run Them All¶
To run the alignment code, you need to choose several parameters. There are three categories of parameters:
* General Parameters
* First Manuscript Parameters
* Second Manuscript Parameters
- General Parameters:
- window size
- model path
- subword count
- First Manuscript:
- begin index
- root path
- page path
- path
- Second Manuscript
- begin index
- root path
- page path
- path
Once the code is executed, a progress output is printed, and finally alignment accuracy is calculated out of those that have confidence rating higher than 1.
g_window_size = 7
g_model_path = 'best_model'
g_subword_count = 140
g_begin1 = 1
g_root1 = '/DATA/majeek/data/multiWriter/0206'
g_page1 = '/004-2'
g_path1 = g_root1 + g_page1 + '/CCs/0206-004-2-'
g_begin2 = 144
g_root2 = '/DATA/majeek/data/multiWriter/0207'
g_page2 = '/003-1'
g_path2 = g_root2 + g_page2 + '/CCs/0207-003-1-'
g_accuracy = align_manuscripts_page(g_root1, g_path1, g_page1, g_begin1,
g_root2, g_path2, g_page2, g_begin2,
g_subword_count, g_window_size, g_model_path)
print('success rate = %2f' % g_accuracy)
Final Words¶
I hope you have enjoyed reading this work. If you have any question or comment feel free to email me at majeek @ cs bgu ac il.
The complete code is found on-line, and can be downloaded freely from my github.
More information regarding my work and me can be found at my webpage, and my linkedin.