Introduction¶
In this work, we've generalized the model trained in the paper released back in ICDAR2017 from writer-specific, to writer-invariant over 7 writing styles. The main purpose was to create one model that is able to detect multiple writing styles without prior training on these specific writing styles.
To show our success in training a writing style invariant model, we executed a complete cross-validation that consists of 21 different tests. In each test, we trained the model on five manuscripts, keeping the last two for validation and testing, and compared the results with the older network architecture - showing solid improvements.
Data Preparation: acquiring the data¶
We begin with data preparation, the input to the neural network. The data is annotated already and we will be using seven manuscripts. The complete seven manuscripts can be found here. The first five are from the VML-HD dataset, and the last two are 0206, and 0207 found at end of the same page. A sample of each manuscript can be seen here:







The data format is simple, for each manuscript we created a special directory, inside it we store all pages of this manuscript. For each page a directory is created, and inside it CCs directory that contains all subword images in this page. A file is also present that contains the list of labels for these subword images. Each manuscript folder contains around 7000 subword images.
The first thing to do is to split the pages folders to two sets, one will be our training set, and the other one will be used for validation and testing sets. These two are split in half after the pairing process.
Resizing the data¶
The images are the original RGB images without any modifications, they were only segmented from the manuscript page following annotation information.
Before creating the pairs, the images need to be reshaped to dimensions of 83 by 69. An already resized dataset of the seven manuscripts can be downloaded here.
Data Preparation: generating pair information¶
We now create the pairs information. The annotated data we use is labeled with its textual value.
The deep Siamese network accepts a pair of images as input, and predicts whether the pair contains the same textual value or not, even if they do not really look the same in writing. If they contain the same textual value, they are called true pair, if they do not, then they are called false pair.
Some examples can be seen here:


The first two images have the same textual label, even though they look differently, mainly due to writing the letter ـهـ differently. The same with the last two images. The writing style of the letter ـى is different, even though they are the same. Both of these cases are marked as true pair in the data. These cases are exactly where the neural network shines in contrary to older techniques.
Now we will proceed to create the pairs information of the 21 tests.
Creating the cross validation tests - 21 in total¶
The code below generates the pair information for all the 21 tests requires to achieve a complete cross validation of the dataset. Each time it choses 5 manuscripts for training, leaving the last two for testing and validation. The whole process is done automatically following the code below.
import os, errno
from os import listdir
import numpy as np
import itertools
import codecs
from os import path
manuscripts = ['0206', '0207', '3157556', '3158466', '3249138', '3368132', '3426930']
manuscripts_path = '/DATA/majeek/data/multiWriter/'
out_root_path = '/DATA/majeek/multiWriterTests/'
train_set_size = 5
def create_pairs(test_number, sets):
subword_map = {}
subword_idx = 0
for type, set in enumerate(sets):
if type == 0:
set_type = 'train'
else:
set_type = 'test_valid'
for first_manuscript in set:
for second_manuscript in set:
if set.index(first_manuscript) >= set.index(second_manuscript):
continue
print('pairing ' + first_manuscript + ' with ' + second_manuscript + ' ...')
first_manuscript_pages = [d for d in listdir(manuscripts_path + '/' + first_manuscript + '/')]
second_manuscript_pgaes = [d for d in listdir(manuscripts_path + '/' + second_manuscript + '/')]
i = 0
for first_manuscript_page in first_manuscript_pages:
print(str(i+1) + '/' + str(len(first_manuscript_pages)))
with codecs.open(manuscripts_path + first_manuscript + '/' + first_manuscript_page + '/' +
first_manuscript_page + '.txt', 'r') as fbFile:
fImages = []
for line in fbFile.readlines():
line = line.decode('utf-8-sig').strip()
imgName, label = line.split('\t')
fImages.append((imgName, label.strip()))
for second_manuscript_page in second_manuscript_pgaes:
pairs = []
labels = []
with codecs.open(manuscripts_path + second_manuscript + '/' + second_manuscript_page +
'/' + second_manuscript_page + '.txt', 'r') as sbFile:
sImages = []
for sLine in sbFile.readlines():
sImgName, sLabel = sLine.decode('utf-8-sig').strip().split('\t')
sImages.append((sImgName, sLabel.strip()))
# now we compare
for fImg in fImages:
for sImg in sImages:
if fImg[1] == sImg[1]:
if fImg[1] in subword_map:
labels.append(subword_map[fImg[1]])
else:
subword_map[fImg[1]] = subword_idx
labels.append(subword_idx)
subword_idx += 1
pairs.append((first_manuscript + '-' + first_manuscript_page + '-' +
fImg[0] + '.png',
second_manuscript + '-' + second_manuscript_page + '-' +
sImg[0] + '.png',
subword_map[fImg[1]]))
try:
path_str = out_root_path + 'test_' + str(test_number) + '/' + set_type + '/pairs/'
os.makedirs(path_str)
print('created ' + path_str)
except OSError as e:
if e.errno != errno.EEXIST:
raise
with codecs.open(path.join(out_root_path + 'test_' + str(test_number) + '/' + set_type +
'/pairs/', first_manuscript + '-' +
first_manuscript_page +
'^' + second_manuscript + '-' +
second_manuscript_page + '.txt'), 'w') as fp:
fp.write('\n'.join('%s\t%s\t%s' % x for x in pairs))
fp.write('\n')
i += 1
return np.array(pairs), np.array(labels)
train_combinations = list(itertools.combinations(manuscripts, train_set_size))
for j, train_combination in enumerate(train_combinations):
create_pairs(j+1, [list(train_combination), list(set(manuscripts) - set(train_combination))])
Creating the pickles: training, validation, and testing sets¶
This section information is mostly the same as the section found here.
Creating Training Set¶
For each two manuscripts out of the 5 for the training set we generate all possible true pairs. Then for each subword form of each two manuscripts we take up max true pairs. This ensures uniform distribution for both manuscript pairs, as well as subword form pairs.
For each true pairs subword form we choose the same number of false pairs instances for each subword form present. For each subword form, we chose those of at least 30 pairs, and at most 300 pairs.
Creating Validation and Testing Sets¶
The creating of both validation and testing sets is exactly the same as in the previous paper. We generate all possible true pairs for the given two manuscripts then we evenly choose pairs up to max true pairs for each subword form.
For each true pairs subword form we choose the same number of false pairs instances for each subword form present.
The Siamese Neural Network: Architecture Code¶
This network consists of several parts:
* Network twin: Convolutional neural network
* Loss function: binary cross-entropy
* Final activation function: sigmoid applied on the absolute linear distance between the Siamese twins.
* Optimizer: Adam
* Metric: accuracyfrom keras.models import Sequential, Model, load_model
from keras.layers import Dense, Dropout, Lambda, Flatten, Input, MaxPooling2D, Convolution2D
from keras.optimizers import Adam
from keras import backend as K
from keras.callbacks import ModelCheckpoint
def create_base_network(input_dim):
seq = Sequential()
seq.add(Convolution2D(64, (5, 5), padding='same', activation='relu', input_shape=input_dim))
seq.add(MaxPooling2D(padding='same', pool_size=(2, 2)))
seq.add(Convolution2D(64, (4, 4), padding='same', activation='relu'))
seq.add(Convolution2D(128, (4, 4), padding='same', activation='relu'))
seq.add(MaxPooling2D(padding='same', pool_size=(2, 2)))
seq.add(Convolution2D(128, (3, 3), padding='same', activation='relu'))
seq.add(Convolution2D(256, (3, 3), padding='same', activation='relu'))
seq.add(MaxPooling2D(padding='same', pool_size=(2, 2)))
seq.add(Convolution2D(256, (2, 2), padding='same', activation='relu'))
seq.add(Convolution2D(512, (2, 2), padding='same', activation='relu'))
seq.add(Flatten())
seq.add(Dense(4096, activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(4096, activation='relu'))
return seq
This is the network twin used in the Siamese neural network. We begin with one Convolution layer, then after each max pooling layer we add two Convolution layers. Then two dense layers separated by a DropOut layer.
Experimental Results¶
We trained the deep neural network over 100 epochs for each test out of the 21 tests. And compare them to our previous deep neural network, showing the improvements gained from adding the additional layers as well as using a different optimizer, making it more suitable as a single model. Instead of training specifically for each pairs of manuscripts, we train once for all manuscripts and generate one model that is able to assist the alignment algorithm in aligning text written in different writing styles.
The main purpose is to show that the model is able to predict successfully whether an input pair, written in writing style never seen before by the model, contain the same textual information.
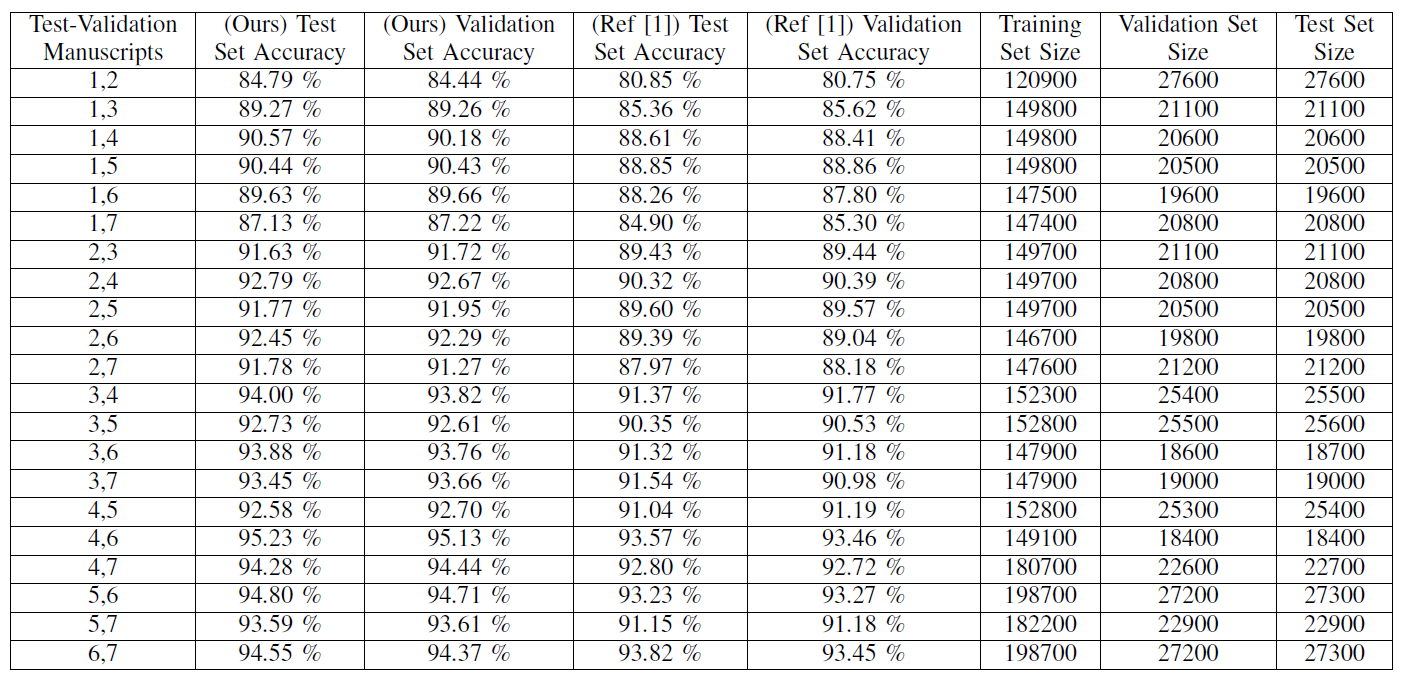
Final Words¶
I hope you have enjoyed reading this work. If you have any question or comment feel free to email me at majeek @ cs bgu ac il.
The complete code is found on-line, and can be downloaded freely from by github.
More information regarding my work and me can be found at my webpage, and my linkedin.